
You can’t out-token bad modeling !
History keeps repeating itself in data. And nobody seems to notice.
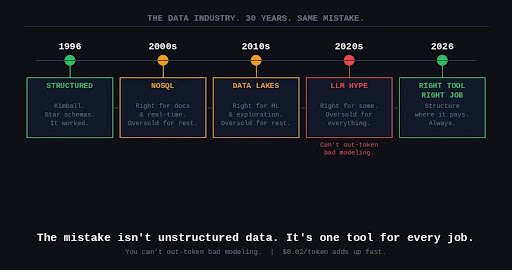
1996.
Ralph Kimball publishes The Data Warehouse Toolkit.
Structured data. Star schemas. Dimensional modeling.
Clean, disciplined, expensive to build, but when it worked, it worked.
Early 2000s.
NoSQL arrives. MongoDB, Cassandra, CouchDB.
“Relational databases are too rigid. Structure is holding us back.”
For document storage, real-time writes, flexible schemas, genuinely useful.
Then oversold for everything else.
2010s.
Data lakes. Hadoop. Snowflake. Databricks.
The pitch: store everything, analyze anything.
For exploration, ML pipelines, document workloads, genuinely powerful.
Then oversold for everything else.
Source-of-truth metrics built on top of data lakes became a reliability nightmare.
2020s.
LLMs arrive. “The AI will organize the chaos.”
RAG pipelines. Vector databases. Unstructured everything.
For exploration, summarization, edge cases, genuinely useful.
Then oversold for everything else.
Why it’s failing: tokens are expensive. $0.02 per token to normalize garbage adds up fast. And you can’t out-token bad modeling.
See the pattern?
Every wave was right for some workloads.
Every wave was oversold for the rest.
LLMs are just repeating it.
The mistake was never unstructured data.
The mistake was pretending one tool fits every job.
Here’s the framework that actually works:
- Entities, source-of-truth metrics, anything you’ll query a million times: structure it
- Document analysis, exploration, edge cases: use the model
- Anything you’ll report on, trust, or act on repeatedly: structure it

I’ve been running data infrastructure for platforms processing 100M+ monthly active users for over a decade. The companies that get this right aren’t picking a side. They’re asking the right question:
“Does this workload need precision or exploration?”
How can I help ?
We don’t sell you a platform and wish you luck.
We build and manage your entire data layer: structured where it pays, flexible where it doesn’t: and we own the outcomes.
The tools changed every decade. The question never did.
What does this data actually need to do?
- Which wave is your data stack still stuck in?
If you’re drowning in data but starving for insight, let’s talk: https://lnkd.in/dBZ8xjEa